One aspect I appreciate about working with AWS is its throve of fully managed, infinitely scalable services like DynamoDB, Lambda, SNS/SQS, S3, etc. Combining them makes it possible to create an infinitely scalable infrastructure without an upfront cost and avoid the extra effort required to manage dedicated servers or platforms like Kubernetes. Sometimes, this may lead to a situation where the project’s backend consists of dozens of services directly influencing each other, resembling some serverless Ruth-Goldberg machine.
The dangers of these kinds of architecture are subtle. Although the components are simple and well-isolated, tracking their interactions can be challenging. Naturally, as any software system grows, interactions between internal components become increasingly complex, involving activities like retries, edge-case scenario paths, legacy compatibility layers, etc. As time goes on, updating this architecture becomes increasingly risky. It is imperative to have up-to-date technical documentation, including dependency diagrams.
When it comes to operating a system, i.e., debugging issues, fixing outages, and providing all kinds of support, the importance of an advanced centralized logging and monitoring strategy becomes evident. Otherwise, tracing what went wrong in a multi-stage process spanning multiple services is a challenging task.
Monitoring, logging, and especially documentation are notoriously hard to get right and maintain long-term. I prefer to choose solutions that provide high levels of observability out of the box whenever possible, avoiding the need for a complex custom monitoring system. AWS Step Functions is one of just such services. It’s a must-have tool for your toolbox if your job entails designing AWS-based architectures.
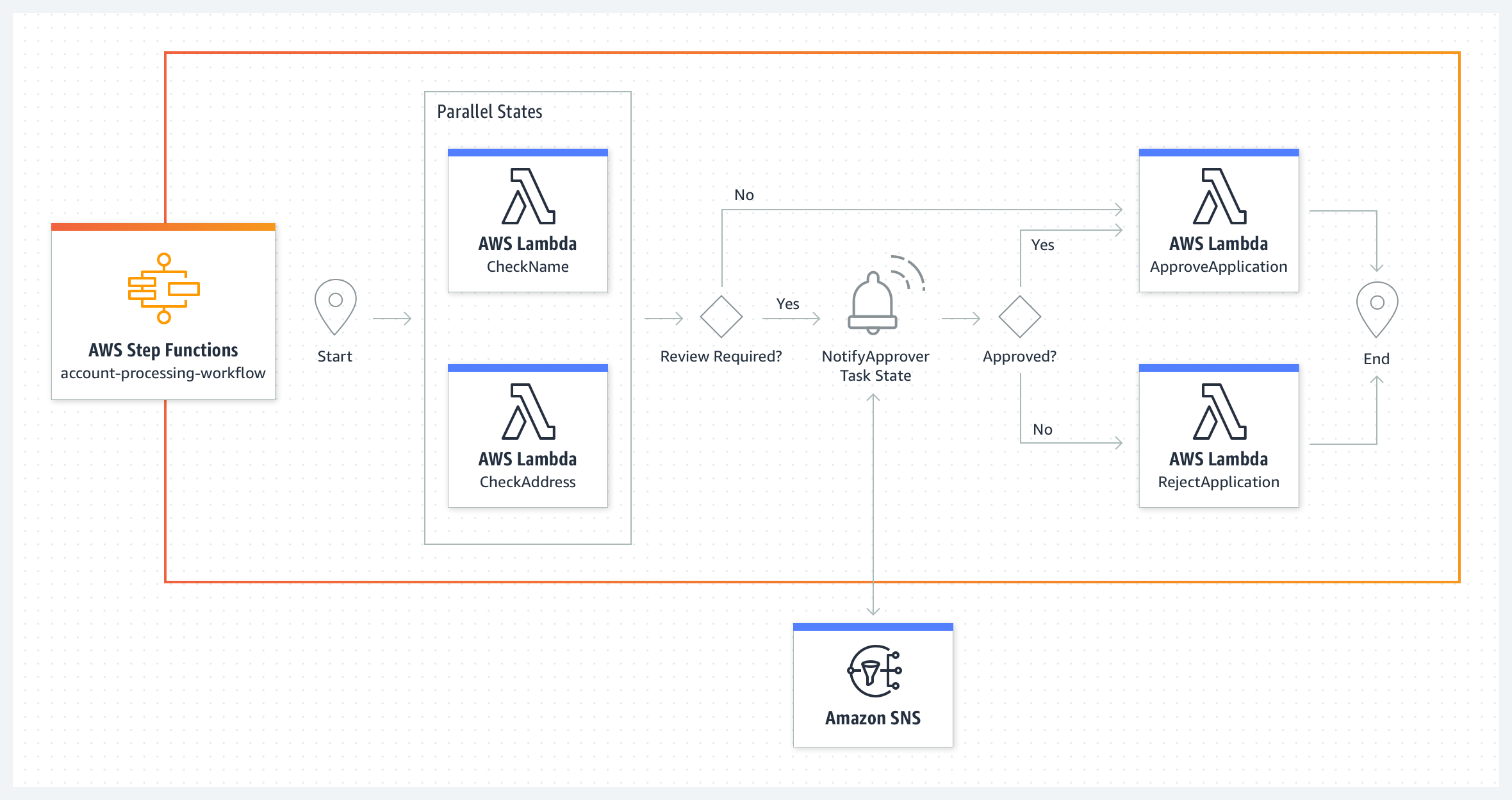 An example of an AWS Step Functions workflow with a manual approval task, from AWS docs
An example of an AWS Step Functions workflow with a manual approval task, from AWS docs
One service to rule them all
Step Functions is a kind of Meta-Service: it coordinates the execution of other services, including potentially those running outside of the AWS ecosystem. You define your process by constructing a State Machine with a JSON-based definition language. State Machine consists of steps and transitions between them, corresponding to nodes and edges in the execution graph. A limited set of logic operations, such as conditionals, are supported out of the box. With a little effort and ingenuity, it is possible to construct any number of complex patterns, such as loops.
A step is the fundamental building block of a State Machine. If you’re defining a State Machine based on an existing serverless architecture hosted in AWS, most of your steps leverage one of the hundreds of existing AWS service integrations: start a Lambda function, put an item into SQS, execute AWS Glue job, etc.
Gluing together calls to multiple unrelated services with different APIs requires adapting argument values. Step Function definitions language allows modifying Step inputs/outputs directly in the step through so-called intrinsic functions. This is a great feature that helps to avoid unnecessary intermediary Lambda function steps. However, the unusual syntax used can take time to understand.
A less well-known but essential feature of the Step Functions service is its ability to integrate with external systems. The integration implementation is amazingly straightforward: State Machine puts task descriptions into the SQS queue for the external system to pick up. Once that system has finished the execution of the task, it reports the result back to the State Machine by making an API call with a unique token obtained from the original SQS message. State Machine execution blocks until the callback arrives.
Benefits of AWS Step Functions
By defining the State Machine, AWS gets information about the architecture of your process as a whole. In return, it provides a central place to describe service interactions and a consistent way to handle state changes.
An execution graph is automatically generated based on task definitions and is guaranteed to stay up-to-date. It’s also possible to see the execution state of every instance of the state machine, which is a great starting point for bug-hunting. Similarly, performance metrics let developers focus on optimizing the slowest steps without rolling out a custom metrics aggregation strategy.
A unified exception-handling mechanism helps build more reliable alerting and incident response systems. A whole run is marked as failed when unhandled failure happens on any step, so there is a single event to listen to and react to.
Step Functions’ architecture and APIs are versatile enough to enable diverse possible use cases. It can be used as an ETL pipeline scheduler (similar to Apache Airflow), as a backbone for a complex alerting system (sending out different notifications to different stakeholders depending on what went wrong with the underlying system), to coordinate automatic provisioning of an execution environment from CI/CD server and in many other capacities.
When to avoid Step Functions
Despite all of the benefits, Step Functions are not a silver bullet. Finding out whether this service can be helpful on a particular project is a complex task. Integrating Step Functions too early or building an overly complex State Machine can lead to counter-productive results.
Step Functions, like any other complex cloud service, require some upfront learning. JSON-based State Machine definition may appear confusing to someone unfamiliar with it. Understanding the nuances of state transitions, error handling, and intrinsic functions may require additional training.
State Machines can potentially execute arbitrarily complex workflows, but they excel in service orchestration and are designed for that use case; bringing business logic to this level mixes responsibility domains, makes testing more challenging, unnecessarily complicates the execution graph, and potentially makes business logic harder to understand by hiding parts of it from source code. Keep the business logic in the code.
Consider which process you wish to represent as a State Machine and evaluate if this representation is suitable. Does it have a distinct beginning and end? Does it contain numerous relatively independent stages? Are these stages mostly synchronous? If an answer to any of the previous questions is “no,” Step Functions is likely not the right tool for the job.
Defining a workflow in a Step Function by design creates a cross-cutting concern. Ensure it does not interrupt the existing work organization, deployment dependencies, or cross team boundaries. Sometimes, to avoid these issues, using Step Functions to manage just a tiny part of the whole process might be for the best.
As always, the most essential part is to understand the tradeoffs that the service provides. And if you’re looking for assistance with your AWS architecture challenges, feel free to reach out to me at freelance@scorpil.com.