In Part One of the “Understanding Generative AI” series, we delved into Tokenization - the process of dividing text into tokens, which serve as the fundamental units of information for neural networks. These tokens are crucial in shaping how AI interprets and processes language. Building upon this foundational knowledge, we are now ready to explore Neural Networks - the cornerstone technology underpinning all Artificial Intelligence research.

A Short Look into the History
Neural Networks, as a technology, have their roots in the 1940s and 1950s. During this period, pioneering scientists like Warren McCulloch and Walter Pitts laid the foundation with their development of a computational model for neural networks, drawing inspiration from the then-limited understanding of how neurons in the human brain transmit and process information. McCulloch’s tenure at the Research Laboratory of Electronics at MIT, starting in 1952, was particularly influential. His team’s research into the visual system of frogs, building upon his 1947 paper, revealed that the eye provides pre-processed and partially interpreted information to the brain, rather than just a raw image. This discovery echoes the concept of tokenization, as discussed earlier, highlighting an early understanding of data processing principles similar to those used in modern AI.
The late 1950s saw further advancement with Frank Rosenblatt’s introduction of the perceptron, a significant early model in machine learning. These initial models set the stage for future breakthroughs, notably the development of backpropagation algorithms in the 1980s. This was a pivotal moment, enhancing the training of multi-layer networks and leading directly to the deep learning revolution. The introduction of transformer models in the 2010s, particularly for natural language processing tasks, represented another quantum leap. These models, relying on self-attention mechanisms, have drastically improved the ability of neural networks to handle sequential data, offering significant improvements in language understanding and generation, and are now a cornerstone of contemporary AI applications.
Neural Network Architecture
Computers excel at storing, matching, and processing precise values, yet for the longest time, they struggled with a task humans effortlessly perform: generalizing concepts. A computer can store and reproduce millions of cat pictures, but this alone does not enable it to decide whether a new image is an image of a cat or not. It seems that our brains are equipped with unique mechanisms that assist us in generalizing and categorizing objects, capturing their abstract essence. This fundamental disparity in how computers and the human brain process information has been a major area of focus in AI, especially in the early stages of neural network development.
Conceptually, a Neural Network is composed of a layered structure of nodes, commonly known as ’neurons’, interconnected by links that transmit signals. This design is inspired by the human brain, where each neuron acts as a distinct processing unit. In these networks, the strength of connections between neurons, referred to as their weight in professional terminology, is critical in determining how the network processes and interprets data. Each neuron receives input signals, multiplies these by its connection weights, and applies a specific function to determine its output. As data traverses through the network, these weighted connections collectively encapsulate abstract concepts shaped by the network’s training. This capability to encode and generalize from imprecise relationships enables neural networks to not only recognize complex patterns in input data but also to generate new data based on these learned abstract patterns. The network’s ability to synthesize and extrapolate from its training equips it to perform tasks such as image and speech generation, effectively translating intricate inputs into meaningful outputs, thereby emulating the generalization prowess of the human brain.
But for neural network to be usable, correct weight need to be set for each connection between the neighbouring neurons. The process of adjusting those weight is what’s called a Neural Network training. During the “training” stage, the network is fine-tuned by adjusting the strength of connections between each node. For each training data element (e.g. picture of a cat), a special algorithm finds a way to modify the “weight” of each connection in a Neural Network in such a way as to make minimal changes, while ensure the desired result - in this case, enabling the network to recognize a cat in an image.
Supervised Learning and Backpropagation
The algorithm responsible for this fine-tuning process is commonly referred to as “backpropagation.” This term stems from the method’s approach to adjusting weights: it starts from the desired output and works backward, in a direction opposite to the normal signal propagation. By doing so, backpropagation calculates the error between the network’s output and the desired result for each training data instance. It then distributes this error back through the network, adjusting weights to reduce the error in future predictions. This reverse flow is what gives backpropagation its name.
While often referred to in the singular, backpropagation is not a single, rigid algorithm but rather a family of algorithms sharing a common principle. This principle involves adjusting the weights of a neural network based on the error rate obtained in the previous epoch (i.e., iteration of learning). However, within this family, there are variations in approaches and techniques. For instance, different optimization algorithms like Gradient Descent, Stochastic Gradient Descent, and mini-batch learning can be employed in the backpropagation process, each bringing nuances in efficiency and effectiveness, especially in dealing with large datasets.
Unsupervised Learning
In addition to backpropagation, there are alternative methods for training neural networks, particularly useful in scenarios where the network is trained to understand data without a pre-set goal in mind (such as distinguishing cats in the example above). This type of learning is known as “unsupervised learning.” In unsupervised learning, different methods are used to adjust neuron connection weights. These methods involve the network identifying patterns, correlations, and structures in the input data autonomously.
Unlike supervised learning, where the model is trained with labeled data, unsupervised learning algorithms work with unlabeled data, making them ideal for exploratory data analysis, clustering, and dimensionality reduction tasks. Common unsupervised learning techniques include k-means clustering, principal component analysis (PCA), and autoencoders. Each of these approaches enables the neural network to develop an internal representation of the input data’s underlying structure, leading to insightful discoveries and pattern recognition without pre-defined labels or categories.
Hybrid Learning Strategies
Modern Large Language Models (LLMs) are not trained using strictly unsupervised or supervised learning methods; rather, they often employ a blend of both. Supervised learning, while effective, is resource-intensive as it requires a labeled dataset, which is challenging to create at the scale necessary for LLMs. Unsupervised learning, more feasible for handling large datasets, offers less control over what the neural network learns, as researchers cannot directly influence the learning outcomes. To address these limitations, researchers have developed innovative combined learning strategies.
One such strategy is self-supervised learning, where the neural network generates its own labels from the training data. This approach enables the model to leverage large volumes of unlabeled data while still maintaining some structure in the learning process. Another strategy is weakly-supervised learning, where the model is trained on a mix of labeled and unlabeled data. This method often involves using a small amount of high-quality, labeled data alongside a much larger set of unlabeled data, thereby balancing the precision of supervised learning with the scalability of unsupervised learning. These hybrid approaches allow LLMs to learn more effectively and efficiently, making the most of vast datasets without being limited by the need for extensive labeled data.
Moreover, different types of Neural Networks can be synergistically combined to solve specific tasks, harnessing the strengths of various learning approaches. A popular strategy in image processing involves using a Neural Network trained via unsupervised learning to interpret and analyze an image, extracting its features and understanding its content. Subsequently, a smaller Neural Network, trained using a supervised learning approach, is employed to assign labels to the image. This method effectively merges the broad interpretative power of unsupervised learning with the precision of supervised learning. By doing so, it takes advantage of the unsupervised network’s ability to discern intricate patterns and the supervised network’s capacity for accurate classification. This combination not only enhances the overall performance but also optimizes the processing efficiency, making it a robust approach for complex image recognition tasks.
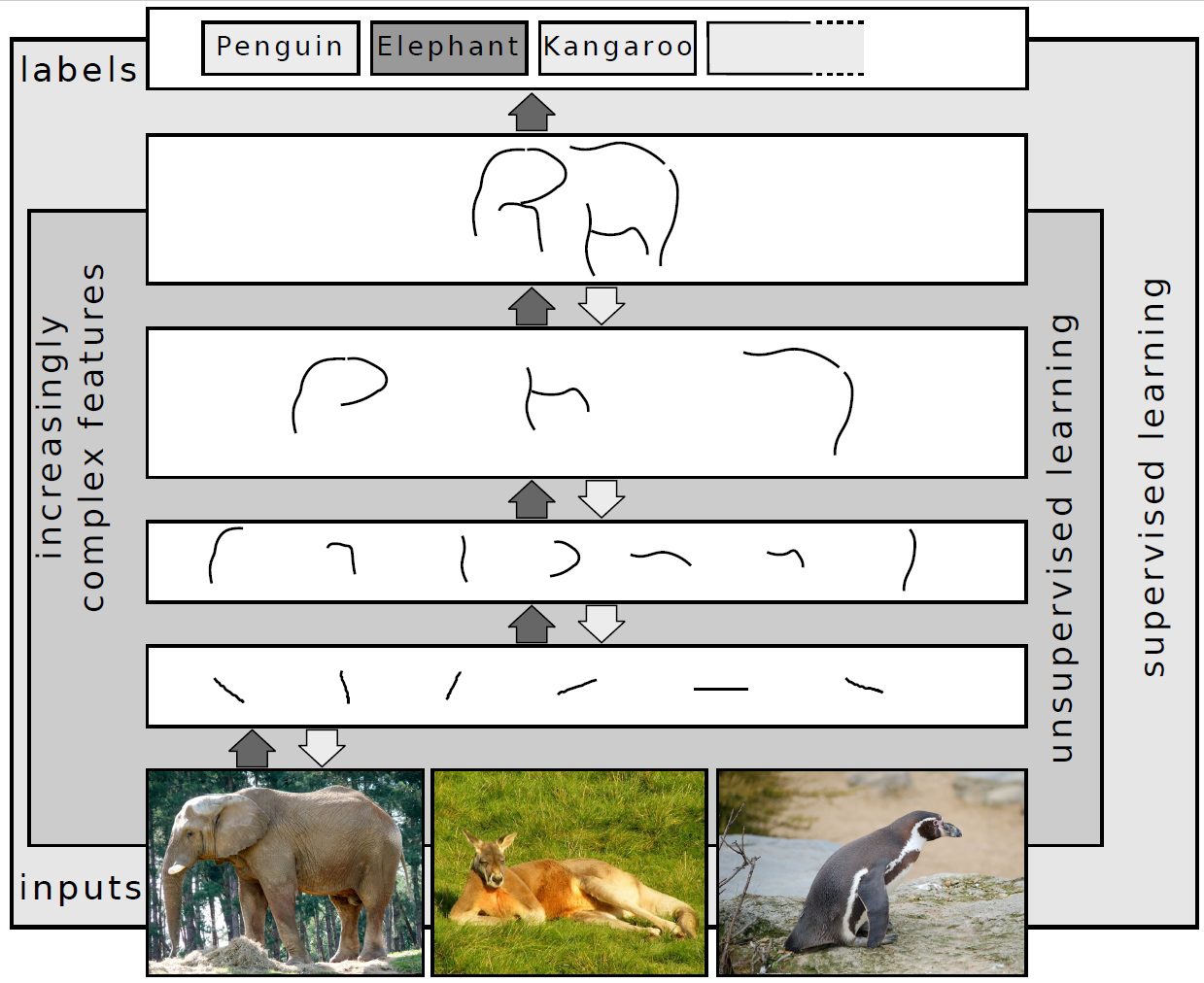 Neural Network using a combination of supervised and unsupervised learning to label objects on an image. Illustration by Sven Behnke CC-BY-CA
Neural Network using a combination of supervised and unsupervised learning to label objects on an image. Illustration by Sven Behnke CC-BY-CA
Knowledge in the Wires
It’s very interesting to observe how such an abstract thing as “knowledge” or “understanding” gets compacted into the graph structure of Neural Network. For example, when trained on images, the layers of a neural network tend to learn features of increasing complexity. The initial layers might recognize basic patterns like edges and textures. Intermediate layers will use these primitives to identify more complex forms like shapes or specific features (like eyes or wheels). Finally, the deeper layers combine these elements to recognize complete objects (like faces or cars). Number of layer in a Neural Network in professional jargon is called its depth, this is where the term “Deep Learning” comes from: learning through multi-layered neural network.
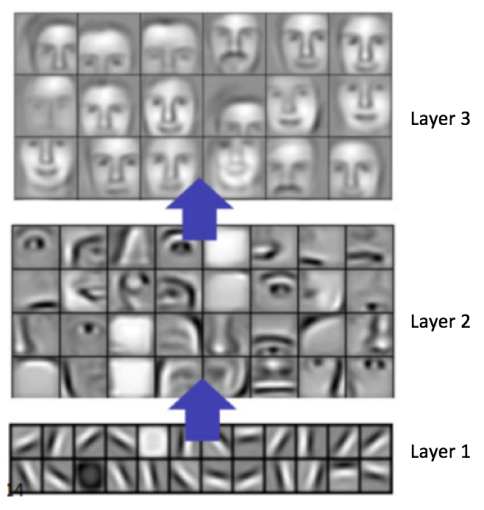 Each layer in a Neural Network builds on the previous one to learn increasingly complex features. Source
Each layer in a Neural Network builds on the previous one to learn increasingly complex features. Source
Certainly, having more layers in a neural network doesn’t always equate to better performance; there is a point of diminishing returns. Determining the optimal number of layers for a specific task is not guided by a universal formula. Instead, this decision, much like choosing among the myriad of variable parameters and techniques applicable to a neural network, is often made empirically. It relies on the researcher’s experience, experimentation, and a thorough analysis of numerous benchmarks.
The “Large” part of “Large Language Models” term refers to a number of neuron connections the models are comprised of. Llama-2, an Open Source and Open Weights LLM developed by Meta, comes in three versions: with 7, 13, and 70 billion parameters. GPT-4 is said to have around 1.8 trillion parameters.
Advanced Techniques
The techniques discussed in this post represent just the beginning of the vast and dynamic world of Generative AI. Neural Networks are a fundamental component of modern Generative AI, but they are only one piece of a much larger puzzle. Contemporary advancements that have propelled Generative AI to new heights include, but are not limited to, the following:
- Transformers: Pioneering models that have revolutionized natural language processing. They use self-attention mechanisms to process sequences of data, such as text, more effectively than previous models. This technology has been a driving force behind the latest AI advancements, enabling more nuanced and context-aware language generation and understanding.
- Diffusion Models: These are a class of generative models that learn to create data by reversing a diffusion process. Starting with a pattern of random noise, diffusion models gradually refine this noise into a coherent output, whether it be an image, sound, or text. This process of learning from noise to structured data has shown remarkable results in generating high-quality, realistic outputs.
- Mixture of Experts: This approach involves dividing a single task into multiple subtasks, each tackled by specialized Neural Networks known as ’experts.’ By leveraging the strengths of different expert networks, this strategy enables more efficient and accurate problem-solving. It’s particularly effective in complex tasks that require diverse knowledge and skill sets, as each expert network can focus on a specific aspect of the problem. GPT-4 is said to use Mixture of Experts approach.
- Generative Adversarial Networks (GANs): A powerful tool in the generative AI toolkit, GANs consist of two neural networks – a generator and a discriminator – that work in tandem. The generator creates data (like images), and the discriminator evaluates it. Over time, the generator gets better at producing realistic data, and the discriminator gets better at distinguishing real from generated data. This adversarial process has been particularly influential in the fields of art generation, photo-realistic image generation, and more.
Each of these techniques contributes uniquely to the field, enhancing the capabilities and potential applications of Generative AI. Together, they represent the cutting edge of AI research, continuously pushing the boundaries of what machines can learn, interpret, and create.
The Journey Ahed
Neural Networks, with their deep roots and transformative advancements, have laid a strong foundation for the extraordinary capabilities of modern AI systems. However, the journey doesn’t end here. In fact, we only scratched the surface.
In future posts of the “Understanding Generative AI” series, we will dive deeper into the advanced topics and emerging trends that are shaping the future of this technology. We’ll explore the intricacies of groundbreaking models like Transformers and GANs, unravel the complexities of diffusion models, and examine the innovative applications of Mixture of Experts. Each of these topics represents a key piece in the vast puzzle of Generative AI, offering new perspectives and understanding of how these technologies are not just mimicking human intelligence but also creating new forms of creativity and problem-solving.
Stay tuned for more insightful explorations into the dynamic world of Generative AI, where innovation and imagination meet to redefine the boundaries of technology and creativity.